|
|
 |
| YAC Text Recoder |
 |
A program for assigning numeric codes to responses to open-ended questions.
Responses to open-ended questions, in their source form, are hard to analyze.
Hundreds of ways an idea can be written down and transcription errors mean that
quantitative analysis is possible if these responses are earlier processed into a more consistent format.
This is what Text-Recoder does - it helps you find similar texts in respondents' responses,
lessens the impact of typos on the analysis and allows for assigning numeric codes to every response.
Data thus transformed can be analyzed quite easily.
Details:
The main window displays the list of responses; it is also used to assign numeric codes to those responses.
In the first column, the count for each response is also displayed (+99 meaning at least 100 occurrences).
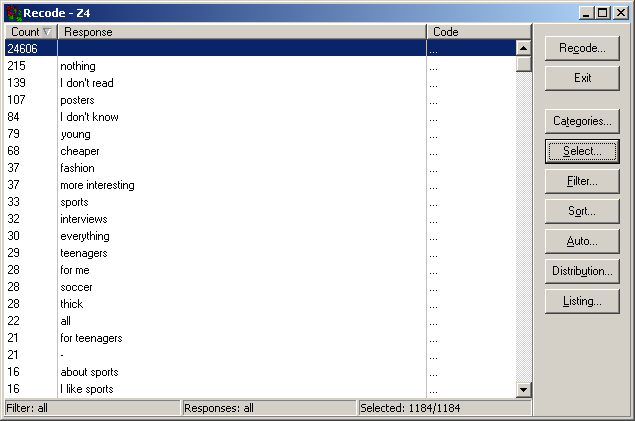
The user can analyze responses to several questions at the same time (this makes sense if these questions
treat with the same topic, and the responses are from the same "range"). A single question can consist of
several data variables/columns that contain the open responses. This allows for a consistent assignment of codes
to the same responses to different questions. It also helps in determining which responses are the important ones
(by analyzing the counts of responses assigned to the same code).
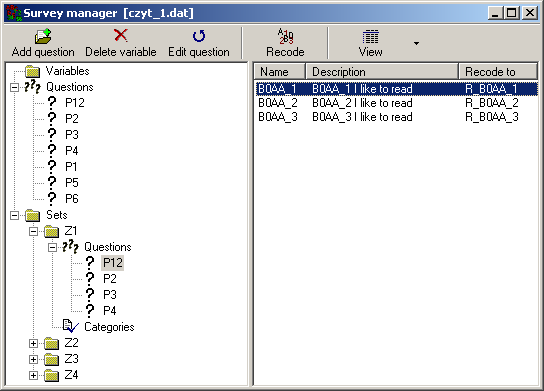
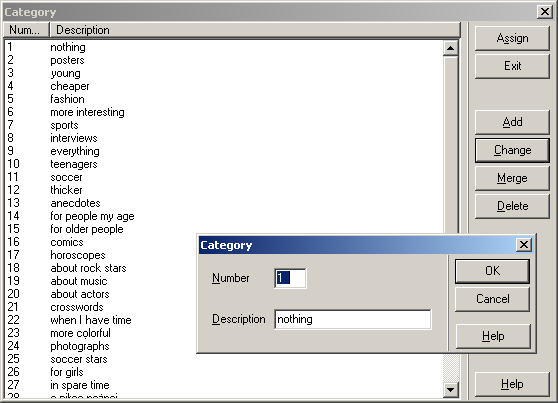
Response categories are defined in another dialog window.
Category marked with the "..." code is treated as a missing / unassigned category.
Categories can be merged, and of course, you can change the text and the code assigned to a category
(this will be automatically reflected in the main list of responses and assignments).
Top
To help in the analysis of a potentially very long list of responses,
the user can sort and filter the list by several criteria.
The list of responses can be sorted by their counts, alphabetically or by the assigned numeric codes.
Thus, you can easily check which responses belong to which category or which responses are not assigned to any category yet.
Responses can also be filtered depending on the text.
The list can be limited to those responses that fit, start with, or include the given pattern.
You can use basic regular expressions to define patterns - characters "?" and "*" that specify respectively:
any character or any sequence of characters (empty too, just as you can do when specifying a list of files).
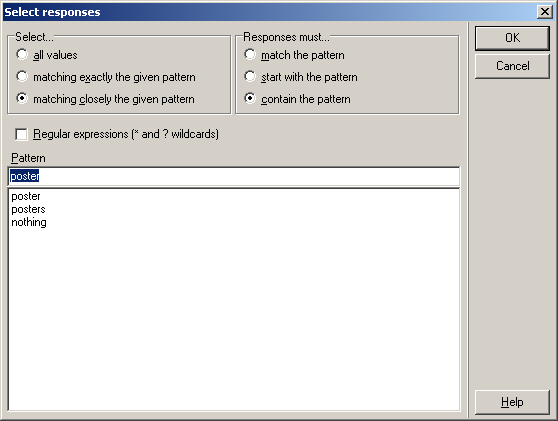
Moreover, the application can search for responses similar to the given text.
This diminishes the impact on your work of typos in the response texts (please note the response "psters" below).
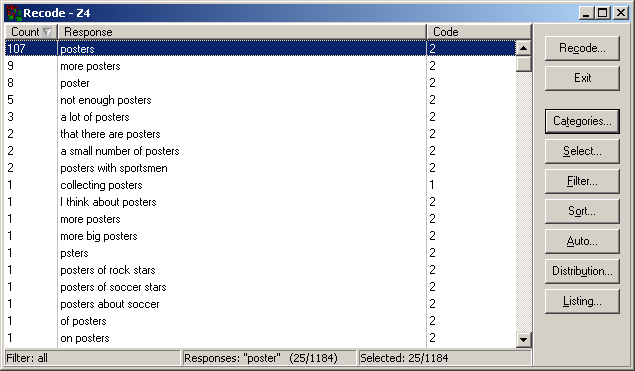
The list of responses can also be restricted to those given by a sub-group of respondents.
Filter expressions can be defined based on all numeric variables in the data file:
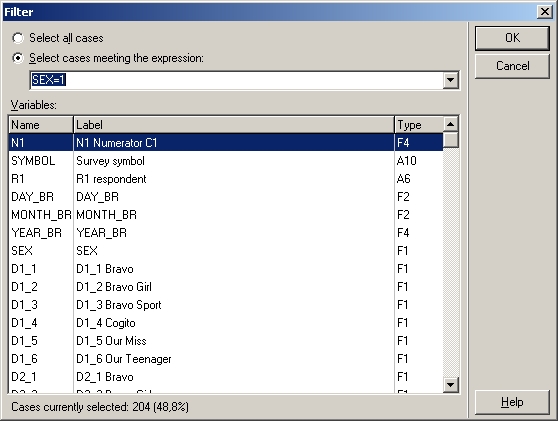
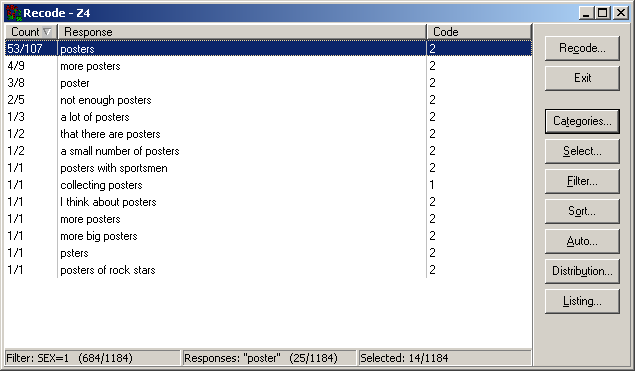
Filters can include arithmetic, comparison, and logic operators, e.g.: SEX = 1 | ( INCOME > 5 & CITY > 1 ).
Top
So, a typical working session might look as follows:
- display all responses sorted by counts,
- select the response with the highest count that doesn't yet have a numeric code assigned,
- define a new category that has the same text as the response from p. 2),
- find all responses similar to the one from p. 2),
- assign the category from p. 3) to all responses found in p. 4) that don't have a numeric code assigned yet.
Repeat the above procedure as long as the new category has a "reasonable" number of responses
(for instance, there's no sense in defining a new category for a response that appears only once).
The above procedure seems pretty easy to automate.
And so it was done (the categories displayed above as well as assignments of codes to responses
were done by this auto-coding procedure):
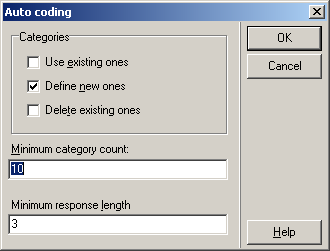
The difference between this auto-coding procedure and the one described a bit earlier
is that the program will consider only those responses that are longer than the given number of characters
(everything is similar to very short texts).
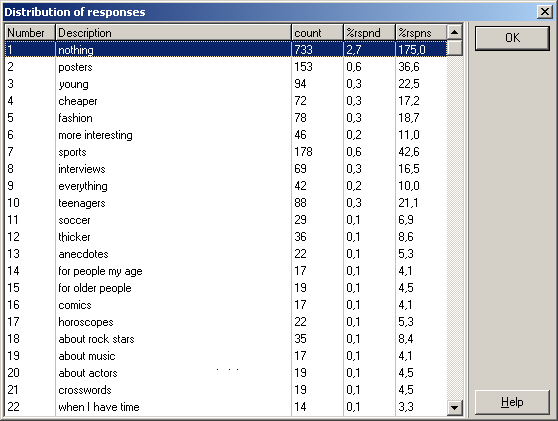
You can also check the frequencies of categories (the counts of all responses in a given category
are summed up in the dialog window below):
Top
There are several other functions in the program:
- Listing - saves the list of all responses with counts and assigned codes to a text file,
- SPSS data import - the program works on Fixed ASCII data, but can import SPSS data files (.sav),
- DataGate support - DataGate
data is handled directly by the program,
- SPSS data export - after working with the program, the data is ready to be imported into SPSS;
the data is available in two formats: multi-value variables and dichotomous variables (certain programs handle one, but not the other).
Top
The demonstration version can be downloaded from here.
Top
Changes in consecutive versions of YAC Text Recoder (previously Text-Recoder) are documented below, starting with version 2.00.
- Version 2.07.a
- Added handling of code descriptions containing line breaks -
previously, defining codes with descriptions containing line breaks
would break the format of the .trp project file and the program would no longer be able to open it.
- Fixed handling of long text variables in SPSS data files -
after saving recodes to an SPSS data file,
some long text variables would be visible in SPSS as a set of variables no longer than 255 characters.
- Fixed handling of SPSS data files with numerical values outside of the integer range (such as 1E20) -
an "invalid floating point operation" error would be reported
when trying to save recodes to the SPSS data file.
- Version 2.07 - response (and code) sorting by their similarity to a given string (using DamerauľLevenshtein distance).
- Version 2.06 - automated coding reintroduced.
- Version 2.05.a
- A note on saving codes to the data file was added to help files.
- Various small fixes.
- Version 2.05
- When importing data, the project file is checked for consistency.
- When importing data / opening Fixed-ASCII data, the data file is checked for consistency.
- Various small fixes.
- Version 2.04
- Added handling of long text variables in SPSS data files (up to 32767 characters).
- Added a view box in the recode window that displays full text responses.
- Version 2.03 - added unification options for response texts:
- Default options may be defined in the preferences dialog window.
- Options for sets may be defined in the set edit dialog window.
- Version 2.02.a - fixed handling of SPSS data files with missing value ranges defined.
- Version 2.02
- Faster opening and closing of data files.
- Faster reading of responses.
- Faster recoding of sets.
- Added progress bars when reading responses and recoding sets.
- Versions 2.01.a - 2.01.c
- Fixed handling of SPSS long variable names.
- Importing old Text-Recoder projects enhanced.
- Various GUI fixes.
- Version 2.01 - added demonstration data.
- Version 2.00
- Multiple codes may be assigned to a single text response.
- Non-numeric code identifiers are supported.
- Direct access to SPSS data files (.sav) is supported.
- Code counts are reported on line in the code list of the recoding window.
- Recodes are written to the project file independently of saving numeric data to the data file.
The first version of the application was written in 1994. It worked under DOS and was developed
using Borland Pascal and the Turbo Vision library. At the beginning of 2000,
it was converted to Delphi and Windows. Below is the image of the original, DOS version, of the program (in Polish):
Top
Top
|
|
|
|

