|
|
 |
| YAC Text Recoder |
 |
Program służący do przypisywania kodów numerycznych do odpowiedzi na pytania otwarte.
Odpowiedzi na pytania otwarte, w swej źródłowej formie, są trudne w analizie.
Setki sposobów na zapisanie tych samych myśli oraz błędy w transkrypcji powodują,
że aby móc analizować te dane metodami ilościowymi, muszą one zostać przetworzone na postać bardziej spójną.
Do tego służy program Text-Recoder, który pozwala na wyszukiwanie podobnych informacji w tekstach odpowiedzi,
zmniejsza wpływ literówek na analizę danych i pozwala na przypisanie każdej odpowiedzi kodu numerycznego.
Tak przygotowane dane numeryczne mogą być następnie łatwo analizowane.
Szczegóły:
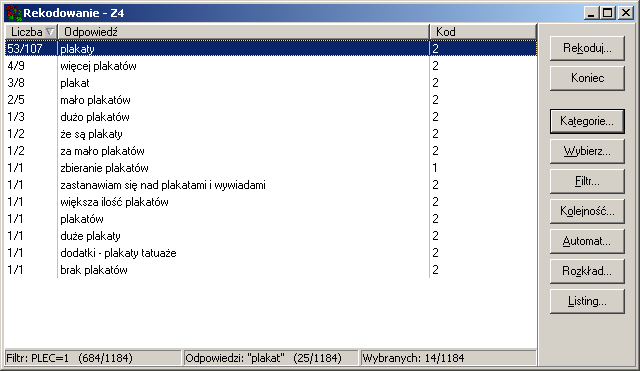
Główny ekran przedstawia listę odpowiedzi, do których można przypisywać kody numeryczne.
Obok odpowiedzi podana jest jej liczba wystąpień w danych źródłowych (gdzie +99 oznacza co najmniej 100 wystąpień).
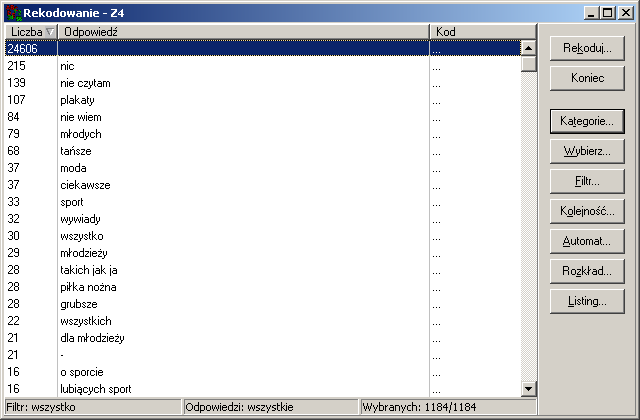
Użytkownik może analizować odpowiedzi z kilku pytań jednocześnie (co ma sens
gdy różne pytania dotyczą tego samego zagadnienia, a odpowiedzi na te pytania
są z podobnych "zakresów"). Na jedno pytanie może składać się kilka zmiennych/kolumn pliku danych zawierających odpowiedzi otwarte.
Pozwala to na jednolite przypisanie kodów do tych samych odpowiedzi z różnych pytań; pozwala też na łatwiejsze określenie,
czy dana odpowiedź pojawia się w danych częściej (i jest warta oddzielnego kodu numerycznego),
czy rzadziej (i powinna być przypisana do kategorii ogólniejszej).
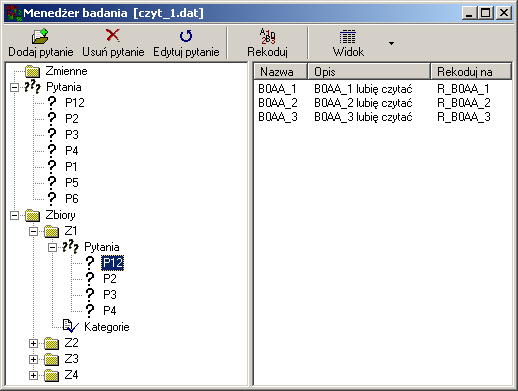
Kategorie odpowiedzi definiowane są w oddzielnym oknie. Kategoria oznaczona kodem "..."
traktowana jest jako brak przypisania kategorii. Kategorie można łączyć,
można też oczywiście zmieniać kod i tekst przypisany kategorii
(co będzie automatycznie odzwierciedlone na głównej liście odpowiedzi i przypisań).

Góra
Aby ułatwić pracę z potencjalnie bardzo długą listą odpowiedzi,
użytkownik ma możliwość sortowania i filtrowania listy odpowiedzi wg kilku kryteriów.
Sortować można po liczebnościach kategorii, alfabetycznie lub też po przypisanych kodach kategorii.
Można więc łatwo sprawdzić, które odpowiedzi znalazły się w jakiej kategorii oraz
które odpowiedzi nie są przypisane jeszcze do żadnej z kategorii.
Odpowiedzi można też filtrować ze względu na tekst. Listę odpowiedzi można ograniczyć
do tych odpowiedzi, które są zgodne z, zawierają lub zaczynają się od podanego wzorca.
We wzorcach można korzystać z podstawowych wyrażeń regularnych -
znaków "?" i "*", które reprezentują odpowiednio: dowolny znak lub dowolny ciąg znaków
(także pusty, jak przy określaniu list plików).
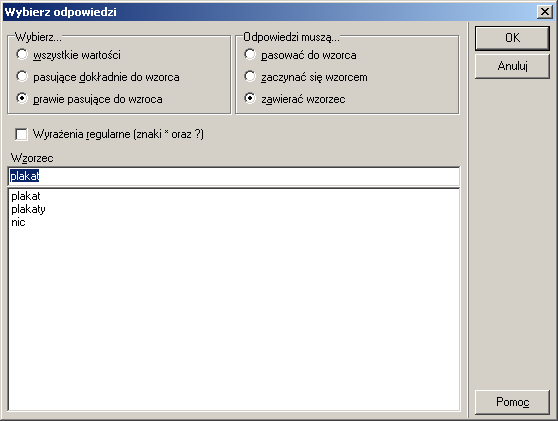
Co więcej, program pozwala na szukanie tekstów podobnych do podanego,
co ogranicza negatywny wpływ na pracę literówek we wpisywanych tekstach odpowiedzi
(proszę zwrócić uwagę na odpowiedź "plakty" poniżej).

Można też ograniczyć listę odpowiedzi do odpowiedzi udzielonych przez zadaną podgrupę
respondentów. Służą do tego filtry definiowane za pomocą zmiennych numerycznych
znajdujących się w zbiorze danych:
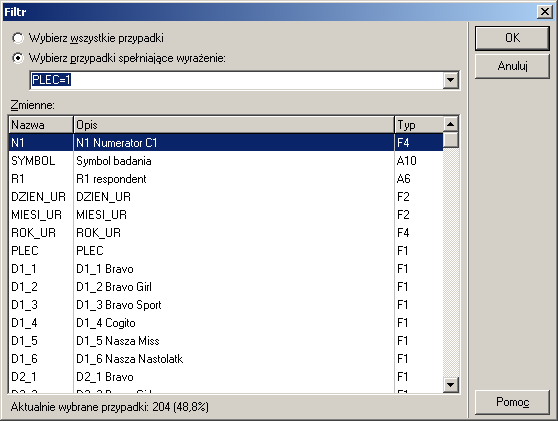
W wyrażeniach dopuszczalne są operacje arytmetyczne,
operacje porównania i operacje logiczne (koniunkcja, alternatywa, negacja).
Filtr może mieć więc postać dosyć skomplikowaną, np.: PLEC = 1 | ( DOCHOD > 5 & MIASTO > 1 ).
Góra
Typowa praca mogłaby więc wyglądać następująco:
- wyświetl wszystkie odpowiedzi posortowane wg liczebności,
- wybierz najbardziej liczną odpowiedź, której nie przypisano jeszcze kategorii,
- zdefiniuj nową kategorię, której tekst jest równy odpowiedzi z p. 2),
- znajdź wszystkie odpowiedzi podobne do odpowiedzi z p. 2),
- wszystkim znalezionym odpowiedziom z p. 4), którym jeszcze nie przydzielono żadnej kategorii, przydziel kategorię z p. 3).
Powyższą procedurę powtarzamy dopóty, dopóki do nowo definiowanych kategorii
włączana jest "rozsądna" liczba wystąpień odpowiedzi (np. nie ma sensu definiować nowych kategorii
dla odpowiedzi udzielonych tylko przez jedną osobę).
Powyższa procedura wydaje się być całkiem łatwa do zautomatyzowania. Tak też się stało (wyżej wyświetlane kategorie
jak i przydziały odpowiedzi do kategorii zostały wykonane auto-kodowaniem):
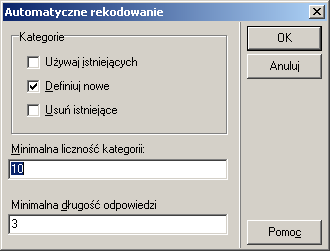
Różnica między procedurą auto-kodowania i opisaną nieco wcześniej polega na tym,
że są brane pod uwagę tylko te odpowiedzi, których długość jest większa od zadanej liczby znaków
(do bardzo krótkich odpowiedzi wszystko jest podobne).
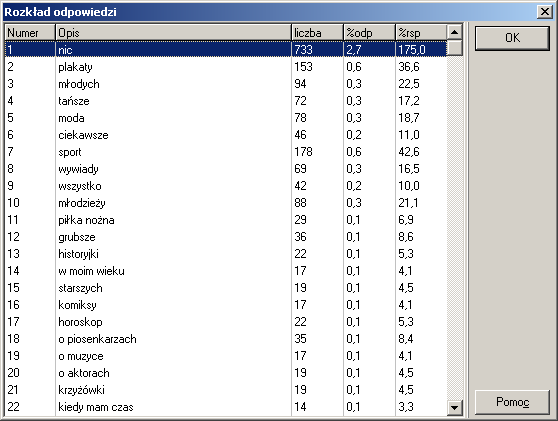
Można też sprawdzić jak przedstawiają się rozkłady kategorii odpowiedzi
(zliczane są tu wszystkie odpowiedzi, które zostały zaliczone do danej kategorii):
Góra
Pozostałe funkcje programu to:
- Listing - zapis do pliku tekstów odpowiedzi wraz z liczebnościami i przydzielonymi kategoriami,
- Import danych z SPSS - program działa na danych Fixed ASCII, jednakże potrafi też importować
dane bezpośrednio z plików danych programu SPSS (.sav),
- Obsługa danych DataGate - dane DataGate
są bezpośrednio obsługiwane przez program,
- Eksport danych do SPSS - po pracy z programem dane są gotowe do wciągnięcia do aplikacji SPSS;
dane dostępne są w dwóch postaciach: zmiennych wielowartościowych oraz zmiennych dychotomicznych (niektóre programy obsługują jedną z nich, ale nie drugą).
Góra
Wersja demonstracyjna programu jest do ściągnięcia tutaj.
Góra
Poniższy temat dokumentuje zmiany programu YAC Text Recoder (dawniej Text-Recoder) począwszy od pierwszej wersji 2.00.
- Wersja 2.07.a
- Dodana obsługa znaków końca linii w opisach kodów -
dotychczas, definiowanie kodów z opisami zawierającymi znaki końca linii powodoło,
że plik projektu .trp nie był prawidłowy i nie mógł zostać ponownie wczytany przez program.
- Poprawiona obsługa długich zmiennych tekstowych w plikach SPSS -
po zapisaniu rekodów do pliku SPSS niektóre długie zmienne tekstowe przedstawiane były
jako zbiór zmiennych tekstowych nie dłuższych niż 255 znaków.
- Poprawiona obsługa plików SPSS z wartościami numerycznymi spoza zakresu liczb całkowitych (np. 1E20) -
błąd "invalid floating point operation" był zgłaszany przy próbie zapisania rekodów do pliku SPSS.
- Wersja 2.07 - sortowanie odpowiedzi (i kodów) po podobieństwie do podanego tekstu (obliczając odległość Damerau-Levenshteina).
- Wersja 2.06 - wznowiona obsługa automatycznego kodowania.
- Wersja 2.05.a
- Do pomocy została dodana notka na temat zapisywania kodów do pliku danych.
- Różne drobne poprawki.
- Wersja 2.05
- Przy imporcie danych, sprawdzana jest spójność definicji w importowanym projekcie.
- Przy imporcie danych / otwieraniu danych Fixed-ASCII, sprawdzana jest spójność danych.
- Różne drobne poprawki.
- Wersja 2.04
- Dodana obsługa plikw SPSS z długimi zmiennymi tekstowymi (do 32767 znaków).
- Dodane okno podglądu długich odpowiedzi tekstowych w oknie rekodowania.
- Wersja 2.03 - dodane opcje unifikacji tekstów odpowiedzi:
- Domyślne opcje można zdefiniować w oknie dialogowym preferencji.
- Opcje dla zbiorów można zdefiniować w oknie edycyjnym zestawów.
- Wersja 2.02.a - poprawiona obsługa plików danych SPSS ze zdefiniowanymi zakresami braków danych.
- Wersja 2.02
- Przyspieszone otwieranie i zamykanie plików danych.
- Przyspieszone wczytywanie odpowiedzi.
- Przyspieszone rekodowanie zbiorów.
- Dodane paski postępu przy operacjach wczytywania odpowiedzi i rekodowania zbiorów.
- Wersje 2.01.a - 2.01.c
- Poprawiona obsługa długich nazw zmiennych SPSS.
- Rozszerzone importowanie starych projektów z programu Text-Recoder.
- Różne drobne poprawki interfejsu.
- Wersja 2.01 - dodane dane demonstracyjne.
- Wersja 2.00
- Możliwość przypisywania wielu kodów do jednej odpowiedzi tekstowej.
- Możliwość tworzenia nienumerycznych identyfikatorów kodów.
- Praca bezpośrednio na plikach danych SPSS (.sav).
- Liczebności kodów podawane na bieżąco w liście kodów w oknie rekodowania.
- Zapisywanie rekodów do pliku projektu niezależnie od zapisywania rekodów do plików danych.
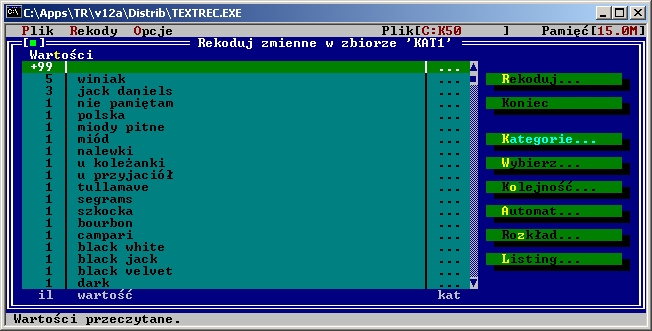
Pierwsza wersja programu powstała w roku 1994. Była to wersja działająca jeszcze
pod DOS-em a została napisana w środowisku Borland Pascal przy użyciu biblioteki Turbo Vision.
Na początku roku 2000 program został przeniesiony pod Delphi i Windows.
Poniżej znajduje się zrzut z ekranu przedstawiający oryginalną wersję DOS-ową:
Góra
Góra
|
|
|
|

